
E2E基盤を一発で用意できるCLIを作った
背景
最近のAIを活用したプログラミングの勢いは凄いですね。 私もClaude CodeやDevinを始めとするAIを活用した開発を日々行っていますが、今までとは完全に異なる速度でフィーチャを届けることが可能になりました。こうした開発速度が上がる中で動作保証のためのガードレールの重要性はさらに高くなったと感じています。
特にE2Eテストを使用したガードレールは強力で、プロダクトがユーザの期待する動作を確実に行えることを担保することで、ドラスティックな変更も容易に行えます。最近は今までは難しかったライブラリの入れ替えなどもAIの利用によって以前よりはるかに速く行うことができ、振る舞いの担保の重要性は高くなってきていると感じています。
私は最近Cloud Spannerを使用しているのですが、Spannerを使用したE2Eテストの環境構築をもっと手軽に行いたいと感じることが多くありました。Emulatorの起動自体は簡単ですが、テストシナリオごとのデータベースセットアップやブラウザ自動化ツールとの統合は手間がかかります。開発用にSpannerを用意するしても料金がかかります。
このような課題の解決を目指して 「spanwright」 を作りました。
https://github.com/nu0ma/spanwright
概要
spanwrightは、Cloud Spannerを利用するプロジェクトでE2Eテスト環境を短時間で構築できるCLIツールです。
npmパッケージとして公開されており、npx spanwright <your-project-name>でテスト環境を構築できます。
構成要素としては下記の要素から成り立っています。
- testfixtures - YAMLベースでseedをDBに投入できるライブラリ
- wrench - Spannerのマイグレーションツール
- spalidate - YAMLベースのSpannerのレコード検証ライブラリ
- Cloud Spanner Go Client - 公式のSpannerクライアントライブラリ
- Playwright - WebアプリのE2Eテストを自動化するブラウザ操作ライブラリ
アーキテクチャ
npx spanwright <your-project-name>を実行すると、下記のようなテンプレートが生成されます。
your-project-name/
├── Makefile # Workflow automation
├── schema/ # Database schemas
│ ├── primary/ # Primary database schemas
│ │ ├── 001_initial_schema.sql
│ │ └── 002_products_schema.sql
│ └── secondary/ # Secondary database schemas (if 2-DB)
│ └── 001_analytics_schema.sql
├── cmd/ # Go CLI tools
│ ├── db-validator/ # Database validation
│ └── seed-injector/ # Data seeding
├── scenarios/ # Test scenarios
│ └── example-01-basic-setup/
│ ├── seed-data/ # JSON seed files
│ ├── expected-*.yaml # Expected results
│ └── tests/ # Playwright E2E tests
├── tests/ # Test infrastructure
├── internal/ # Go internal packages
└── playwright.config.ts # Playwright configuration処理の流れは以下の通りです。
- DockerによるEmulatorコンテナ起動
- wrenchによるDBマイグレーション
- testfixturesを使用した初期データ投入
- Playwrightでシナリオ実行
- DBレコード検証
expected-*.yamlに入っている内容でplaywrightによるブラウザ操作後のSpanner Emulatorの状態と検証できます。
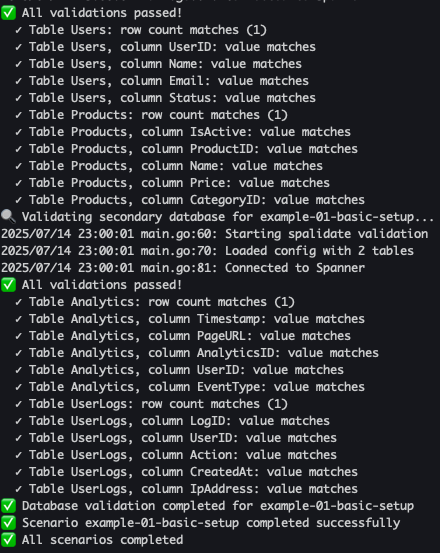 (実際の様子)
(実際の様子)
動くサンプルをexampleに用意しているのでそちらを見れば大体の挙動が把握できるかもしれません。このフレームワークを作成する上でいくつかの発見があったのでそれも書いていきたいと思います。
開発を通じて得られた学び
Claude Codeでの実装体験
このプロジェクトはClaude Codeを使用して開発しましたが、いくつか学びがありました。
E2Eテストの重要性
E2Eテストフレームワークを開発しながらE2Eの重要性を感じるとはこれいかにという感じなのですが、ガードレールの重要性はかなり感じました。このプロジェクトは3回ほど書き直しており、その度にCIによるE2Eテストがガードレールとなり、動作を担保してくれました。具体的にはCIでは実際にテンプレートを作成し、レコード検証まで行っており、end-to-endのテストを実行しています。このE2Eテストがあることで、書き直しの際にも挙動が変わっていないことを担保でき、安心して開発できたと思います。ガードレールの大切さをガードレールを作りながら体感しました。
凝集性
動作が担保できているモジュールを組み合わせることの重要性も感じました。モジュール化で凝集性を担保し、それらを組み合わせることで、安心して開発できました。AIを活用した開発では、モジュール化によりコンテキストが明確になり、より開発スピードも上がったと感じます。
今回開発したフレームワークは、それぞれの動作を独立して行えるライブラリを組み合わせて作成しています。巨人の肩に乗り、Seed投入やスキーマ適用はすでにOSSとして存在するtestfixturesやwrenchを使用し、レコード検証の部分も自作ライブラリspalidateとして切り出しています。
私の好きな記事で、以下のような記事があります。
https://levtech.jp/media/article/focus/detail_666/
まず「持続可能なアーキテクチャとは何か」を改めて検討し、新たなMarpでは「脱Electron」と「モジュール化」を目指すことにしました。モノシリックな構造をやめ、機能ごとに独立した複数のモジュールから構成されるプロジェクトとして、Marpを再構築しよう、と。
spanwrightも、最初はDBレコードの検証やマイグレーションも自前で実装し、1つのモジュールとして開発していましたが、正直破綻していました。E2Eテスト失敗時の原因の切り分けが困難で、どこまで動作が担保されているかも把握するのが難しい状況でした。モジュールに分けて開発することを決めた後は、動作が担保されていることで安心して開発できるようになりました。モジュール化の重要性を開発を通じて実感できたのも大きな学びです。
testfixtures へのプルリクエスト
seedデータ投入には、testfixturesを使用していますが、今回SpannerにJSON型のカラムでエラーが発生しました。原因としては、yamlから変換される文字列を自動的にJSONに変換できないのが理由だったのでPRを出しました。
https://github.com/go-testfixtures/testfixtures/pull/309
現在はマージされリリースされています。testfixturesのコードはGoのinterfaceをうまく使われており、読んでいて勉強になりました。
まとめ
今後も実際に利用しながら、改善を続けていきたいと思います。
https://github.com/nu0ma/spanwright